
Ein SEO-Data-Warehouse gibt dir einen Überblick, über all deine Key Performance Indicators (KPIs) und ermöglicht dir somit schneller Potenziale zu erkennen, Probleme zu identifizieren und regelmäßige To Do’s abzuarbeiten.
Tipp: Auf der SMX München 2022 durfte ich einen spannenden Vortrag zu diesem Thema halten. Schaut mal in die Slides unten rein.
Inhalte
- Wofür brauchst du ein Data Warehouse?
- Womit fängt man an? ETL-Prozess inkl. Tools
Fortsetzung folgt…

1. Wofür brauchst du ein SEO Data-Warehouse?
SEO ist eine zahlenbasierte Wissenschaft, weshalb es zwingend notwendig ist Entscheidungen für Optimierungen auf Basis von Kennzahlen zu treffen.
Spätestens, wenn ein SEO-Update ausrollt und die ersten Anzeichen auf Sichtbarkeits-Verlust stehen, sehnen wir uns danach alle Zahlen auf einen Blick zu haben.
Hierbei kann ein SEO Data Warehouse hilfreich sein, denn es liefert alle Zahlen auf einen Blick und ermöglicht es Muster schneller erkennen zu können. So kann ich bspw. nach dem Gruppieren meiner URLs nach Themengebieten auf einen Blick sagen, ob bspw. „Arzneimittel“ vom Google Update betroffen sind oder nicht.
Auch können mit den gesammelten und aufbereiteten Daten Arbeitssichten gebaut werden, welche automatisiert zu den entsprechenden Sachbearbeitern gesendet werden können. Dadurch lassen sich zeitintensive Arbeitsschritte sparen.
Doch auch, unabhängig von Google Algorithmus Updates können uns Reports innerhalb eines SEO Data Warehouse auf Missstände innerhalb unsere Inhalte aufmerksam machen und uns somit helfen Potenziale schneller zu erkennen und entsprechende Maßnahmen einzuleiten.
2. Womit fängt man an? Der ETL-Prozess

Möchte man ein SEO Data Warehouse aufsetzen, muss man zunächst bedenken, woher man die Daten bekommt, die sich innerhalb dieses Data Warehouse befinden sollen. Sobald man die Daten hat, muss man sie natürlich irgendwo ablegen und um sie auch regelmäßig nutzen zu können, wäre eine Art Reporting von Vorteil.
Für die Erstellung eines Data Warehouse hält man sich am besten an den ETL-Prozess: Extract, Transform, Load.
Im Folgenden zeige ich euch die entsprechenden Schritte im Detail und welche Tools wir dafür genutzt haben.
2.1 Extract – Extrahieren der benötigten Daten
Die Daten für unser SEO-BI können wir uns aus verschiedenen, meist kostenfreien, Datenquellen zusammensuchen. Aktuell benutzen wir auf billiger.de die Daten aus Econda, der Google Search Console sowie die Crawl-Daten aus dem billiger.de-Frontend.

Zum Extrahieren von Daten benutzt man am besten einen Crawler. Der gängigste und auch kostengünstigste Crawler ist die Screaming Frog. SEO Spider Zusätzlich zu den standard Crawling-Daten lassen sich hier noch Custom Extractions anlegen. Durch diese kann man den Crawl komplett auf die jeweilige Website anpassen.

Es eignen sich bei E-Commerce Seiten bspw. sehr gut die Preise, die Anzahl der Produkte auf Listing Seiten oder die Breadcrumb.
Die Daten lassen sich am einfachsten per Xpath extrahieren. Hierzu öffnet man die Google Chrom Dev-Tools und klickt auf das entsprechende Element, das man extrahieren möchte. Über Rechtsklick -> Copy -> Copy XPath kann man den jeweiligen XPath extrahieren.
Exemplarisch ziehen wir uns mal die Breadcrumb auf einer Kategorieseite auf billiger.de per Custom Extraction.
Später ist es wichtig die Konfiguartion des Crawls abzuspeichern, sonst geht wertvolle Arbeit verloren.
Der Crawl lässt sich per Screaming Frog nun im letzten Schritt automatisieren, ich fehle für konsistente Daten mindestens 1 x pro Woche zu crawlen.
Tipp: Da eine Website ein flexibles Gebilde ist, an dem von den unterschiedlichsten Abteilungen gewerkelt wird, ist es wichtig die Custom Extractions mit Hilfe eines Website Monitoring Tools zu tracken. So verwenden wir bspw. Testomato, um die verschiedenen Div-Elemente, die wir extrahieren auf ihr Vorhandensein zu prüfen. Denn wer kennt es nicht, dass ein Entwickler eine kleine Änderung an der Website vornimmt und mal schnell eine HTML-Klasse umbenennt. Schlecht nur, wenn uns das nicht auffällt und somit die Crawls der folgenden Wochen unbrauchbar werden könnten.
Als weitere Datenquelle können wir die Daten aus der Google Search Console extrahieren. Über das Frontend lassen sich ja leider nur 1.000 Zeilen extrahieren, was natürlich für die meisten Websites viel zu wenig ist. Entsprechend müssen wir uns die Daten aus der Search Console API ziehen (LINK). Hier liefert Google die Daten vollständig und über die verschiedenen Reports hinweg in einem File. Diese Daten zu extrahieren, zählt also zu einem der wichtigsten Schritte, da es unsere Daten im Data Warehouse so viel aussagekräftiger machen wird.
2.1 Transform – Daten transformieren
Sobald man die Daten im Screaming Frog vorliegen hat geht es darum sie in eine From zu bringen, damit wir weiter damit arbeiten können. Exrtahiert man bspw. die Anzahl Angebote in einer Kategorie, hat man im Fall von billiger.de noch Text innerhalb des extrahierten Divs stehen. Dieser stört uns natürlich bei der weiteren Verarbeitung der Daten. Entsprechend muss hier gekürzt werden und die Spalte in ein Integer geändert werden. Die Transformation haben wir bei billiger.de per R-Skript gemacht, das geht allerdings auch mit KNIME.
Tipp: KNIME ist ein wunderbares kostenloses Tool, um Workflows abzubilden. Auch kann man mit ihm super das eigene Coden umgehen.
Beim Transformieren kommen wir auch direkt zum Thema Datenbankstruktur. Denn bspw. Custom Extractions werden bei Screaming Frog im Spaltenformat erfasst. Füge ich neue hinzu, verändere ich die Datenbankstruktur. Sprich: Wir sollten die Spalten in Zeilen transformieren (siehe hierzu aber auch der nächste Abschnitt).
2.3 Load – Daten laden & anreichern

Google Big Query: Eine praktische, performante und kostengünstige Lösung für die Datenhaltung.
Das Laden der Daten bedeutet im Grund das Ablegen und Speichern der Daten. Hierfür eignet sich natürlich optimal eine Datenbank. Damit wir die Daten direkt für Google Data Studio (Visualisierung) zur Verfügung haben sollten wir sie am besten Cloudbasiert speichern. Da es sich innerhalb des Google-Universums gut arbeiten lässt, liegt Google Big Query als Datenbank nahe.
Google Big Query ist unkompliziert, schnell und kostengünstig. Trotz der hohen Datenmenge, die wir wöchentlich bei billiger.de crawlen, zahlen wir monatlich lediglich 25 € für Google Big Query.
Generell sollte man beim Aufsetzen der Datenbankstruktur darauf achten, dass diese nicht ständig angepasst werden sollte. Habe ich mich mal für ein gewisses Schema entschieden, sollte ich das möglichst beibehalten, damit die Daten historisch vergleichbar bleiben.
Das bedeutet beispielsweise bei den Custom Extractions, dass wir weg von einem Spaltenformat und hin zu einem Zeilenformat gehen. Der Screaming Frog liefert die Daten in Spalten, fügen wir allerdings neue Custom Extractions hinzu, was innerhalb des Entwicklungsprozesses des Öfteren vorkommt, dann würde sich ständig die Datenbankstruktur ändern. Entsprechend transformieren wir die Spalten in Zeilen. So kommt beim Hinzufügen neuer Custom Extractions immer nur eine neue Zeile hinzu, aber nicht ständig neue Spalten.
Innerhalb des Load Prozess findet außerdem eine Anreicherung der Daten statt. So können wir hier bspw. weitere beschreibende Spalten hinzufügen. Innerhalb des billiger.de SDW haben wir bspw. unsere URLs bestimmten Seitentypen zugeordnet. So steht bspw. in der Zeile mit der URL https://www.billiger.de/show/kategorie/4373.htm in der Spalte daneben „Kategorieseite“. So fällt es uns später leichter die Daten bspw. nach Seitentyp auszuwerten.
Nachdem wir die Daten schön in der Datenbank liegen haben können wir im nächsten Schritt an die sinnvolle Verknüpfung der Daten gehen. Hierzu lassen sich in Google Big Query wunderbar Views anlegen. Sie sind im Grunde genommen vorgefertigte Tabellen, die man über SQL-Statements vorkonfiguriert. Weiß man bspw., dass man regelmäßig alle URLs eines bestimmten Zeitraums (bspw. 3 Monate) in Kombination mit den Frontend-Daten (bspw. Breadcrumb & Anzahl Produkte) abfragen möchte, kann man dafür ein einfaches SQL-Statement bauen. Vorteil hiervon: Die Daten werden in Biq Query berechnet, was den späteren Data Studio Report performanter macht und Daten spart. Bearbeitet man Daten innerhalb von Data Studio wird jedes Mal eine komplette Abfrage der Daten abgefeuert, was schnell teuer werden kann, wenn man noch nicht genau weiß wie der Report eigentlich aussehen soll.
Damit wir die Daten nicht ständig mühselig aus der Datenbank ziehen müssen, wäre natürlich eine schöne visuelle Aufbereitung nicht schlecht. Hierfür bietet sich das bereits erwähnte Google Data Studio an.
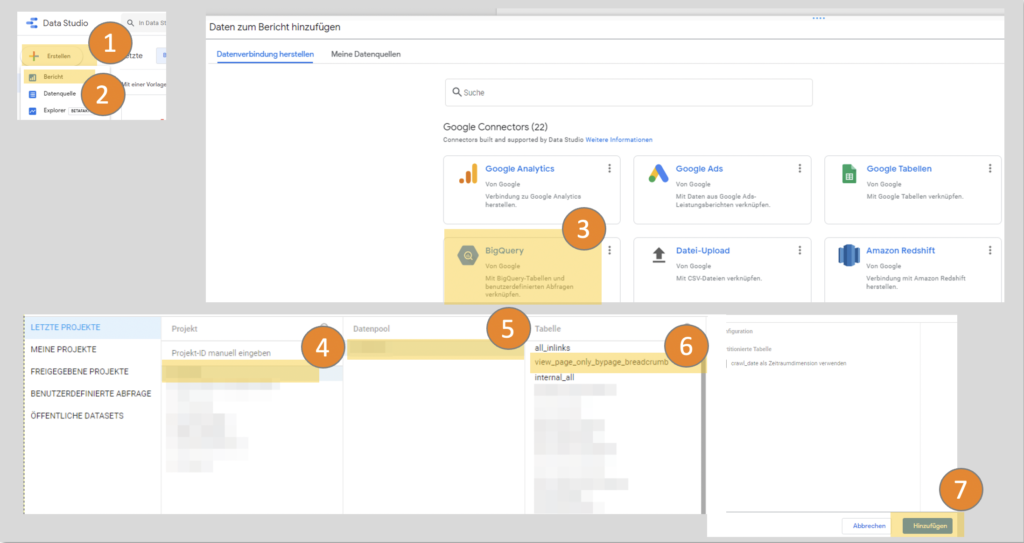
Google Data Studio ist ein weiteres kostenloses Google Tool mit dem ihr eure Daten in Reports & Schaubildern visualisieren könnt. Hierzu müsst ihr zunächst die Datenquellen hinzufügen (1) + (2).
Hierzu geht ihr ins Data Studio, erstellt euren ersten Bericht und lasst euch dann durch das Menü führen. Wenn ihr eure Daten in Big Query liegen habt, müsst ihr nun einfach „Big Query“ auswählen (3), euer Projekt auswählen (4), den Datenpool (5) und dann eure gewünschte Tabelle für den ersten Bericht (6).
Schon habt ihr die Datenquelle verbunden und müsstet beim Erstellen einer Tabelle direkt die einzelnen KPIs/Spalten in Data Studio sehen. Ihr müsstet nun nur noch die gewünschten KPIs rüber in die linke Spalte ziehen und schon tauchen die gewählten Daten in eurer Tabelle auf oder eurem Schaubild auf. Initial ist immer „Record Count“ gesetzt, was so viel wie die Anzahl der Datenpunkte zu einer gewissen Kennzahl bedeutet. Das ist ganz praktisch gemacht, denn so lässt sich direkt abschätzen wie viele Daten ihr abfragen würdet und es gibt einen groben Überblick darüber, ob ihr das gewünschte Ergebnis mit eurer Abfrage/eurer Tabelle erreicht
TIPP: Die Google Search Console lässt sich inzwischen auch direkt mit Data Studio verbinden. So spart ihr euch die Abfrage aus der API und die Datenhaltung in Big Query. Aber Achtung, so könnt ihr nicht auf hsitorische Daten zurückgreifen, denn die GSC speichert nur die Daten der letzten 16 Monate.
Fortsetzung folgt….
This is the perfect webpage for everyone who wishes to understand this topic. You realize so much its almost hard to argue with you (not that I personally would want toÖHaHa). You definitely put a brand new spin on a subject that has been written about for a long time. Great stuff, just great!
Thank you so much! I promise there will be a continuation soon! 😊